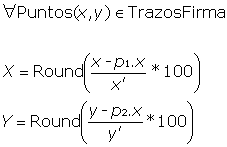Fecha: 2002/2003
Reconocimiento y verificación de firmas manuscritas off-line basado en el seguimiento de sus trazos componentes
Autor: Alejandro Pérez Hernández (alex@esolva.com)
Figura 1. Diferentes ejemplos de firmas
Figura 2. Aplicación de investigación y pruebas
Figura 3. Aplicación definitiva. Verificación y reconocimiento de firmas
Figura 4. Estructura del código del proyecto
Figura 5. Esquema propuesto de implantación del sistema
Figura 7. Variación de la firma
Figura 8. Diagrama de bloques de un sistema de reconocimiento de formas
Figura 9. Diseño de un sistema de reconocimiento de formas
Figura 10. Notación esqueletizado
Figura 11. Ejemplo de transiciones
Figura 12. Original esqueletizado
Figura 13. Resultado esqueletizado
Figura 14. Esquema de una red de neurona
Figura 16. Matriz de convolución aplicada
Figura 18. Resultado aplicar matriz de convolución
Figura 19. Matriz convolución 0º
Figura 20. Matriz convolución 90º
Figura 21. Matriz convolución 135º
Figura 22. Matriz convolución 45º
Figura 23. Resultado matriz 0º
Figura 24. Resultado matriz 90º
Figura 25. Resultado matriz 45º
Figura 26. Resultado matriz 135º
Figura 27. Aproximación realizada
Figura 28. Robustez frente a la pequeña rotación
Figura 29. Relaciones de vecindad
Figura 30. Ejemplo píxeles sin etiquetar
Figura 31. Resultado seguimiento sensible a píxeles sin etiquetar
Figura 32. Tabla de direcciones
Figura 33. Ejemplo de seguimiento
Figura 35. Búsqueda con retroceso
Figura 36. Tipo de datos TipoTrazo
Figura 37. Tipo de datos TPoint
Figura 39. Caja de Feret sobre los trazos
Figura 41. Extracción de los trazos y cálculo de la caja de Feret
Figura 42. Resultado normalización
Figura 43. Ajuste de distancias (distance matchig)
Figura 44. Ajuste elástico (elastic matching)
Figura 45. Ajuste basado en las distancias
Figura 46. Tabla de aprendizaje
Figura 47. Tabla de validación
Figura 48. Base de datos de aprendizaje
Figura 49. Base de datos validación
Figura 50. Reconocimiento de firmas
Figura 51. Verificación de firmas
Índice general1.1. Justificación y aplicaciones
1.3.1. Requisitos funcionales:
1.3.2. Requisitos no funcionales:
1.4. Esquema propuesto de la solución
2 . Fundamentos del reconocimiento de formas
2.1. Reconocimiento on-line y off-line
2.1.1. Ventajas e inconvenientes
2.2. Propiedades de la escritura manuscrita
2.3.2. Diagrama de bloques de un sistema de reconocimiento de formas
2.3.3. Diseño de un sistema de reconocimiento de formas
3.1. Etapas de preproceso de firmas
3.1.1. Limpieza y eliminación del ruido
3.2. Técnicas de etiquetado de trazos
3.2.4. Matrices de convolución
4 . Extracción de características
4.2. 8-vecinos y relaciones de proximidad
4.3. Algoritmo de seguimiento y extracción de trazos
4.3.1. Seguimiento de trazos sensible a píxeles sin etiquetar
4.3.2. Prioridad en las transiciones
4.4. Codificación de los trazos
4.5. Cálculo de la caja de Feret
4.6. Normalización de los trazos
5 . Reconocimiento basado en trazos
5.2. Ajuste de curvas (curve matching)
5.2.1. Ajuste de distancias (distance matching)
5.2.2. Ajuste elástico (elastic matching)
5.3. Combinación de clasificadores
7.1.3. Otra métrica de interés
APÉNDICES
A. BASE DE DATOS DE FIRMAS
B. IMPLEMENTACIÓN
C. BREVE MANUAL DE USUARIO
D. GRAFOLOGÍA
BIBLIOGRAFÍA
El reconocimiento y verificación de firmas en numerosos documentos, entre ellos los bancarios, son unos procedimientos que se están realizando de forma generalizada de manera manual. En este proyecto, se propone un método y una implementación del mismo que sea capaz de realizar estas tareas automáticamente y de forma satisfactoria, con unos costes en tiempo y memoria reducidos que lo hagan competitivo frente al tratamiento manual.
Para lograrlo, el sistema desarrollado será capaz de realizar un preproceso basado en el esqueletizado, etiquetará los puntos de la firma según su pendiente utilizando matrices de convolución, realizará un seguimiento y una extracción de los trazos etiquetados siguiendo un esquema de búsqueda con retroceso, normalizará el tamaño de los trazos y mediante un proceso de ajuste de distancias (distance matching) calculará el porcentaje de similitud entre las colecciones de trazos extraídas de dos firmas. En ese momento el sistema será capaz de reconocer una firma, buscando en la base de datos creada para tal fin, aquélla que más se le parezca, es decir, la que tenga mayor porcentaje de similitud.
Por último y para dotar al software de la capacidad de verificar firmas habrá que calcular el umbral a partir del cual se podrá decir que dos firmas son lo suficientemente parecidas como para pertenecer al mismo firmante.
El grado de fiabilidad logrado en los experimentos realizados hace esperar que las tareas de verificación y reconocimiento de firmas puedan ser automatizas en gran medida, contribuyendo a la reducción del número de fraudes por falsificaciones.
1. Introducción
Hasta fechas recientes, el problema del reconocimiento de firmas en documentos bancarios ha sido obviado o relegado a la responsabilidad de las personas. Esto podría atribuirse a la necesidad de altas capacidades de cómputo, a su complejidad técnica o a que no es el problema más importante para una Entidad Bancaria.
El hecho de que durante muchos años no se dieran las condiciones óptimas para llevar a cabo estos proyectos, y en muchos casos el problema se haya apartado de las prioridades de la banca, no impide que la misma siga asumiendo riesgos, ya innecesarios, a la hora de tratar aquello que resulta vital para su negocio: las firmas de sus clientes y su verificación. Las consecuencias de no asumir por parte de la entidad algún tipo de tecnología que, en mayor o menor medida, permita la autenticación de firmas fuera de la oficina donde se originan las mismas implica, entre otros, los siguientes factores negativos:
Riesgos económicos en caso de operaciones fraudulentas.
Empobrecimiento de la imagen ante los clientes.
Imposibilidad de ofrecer todos los servicios en todas las oficinas. (cancelación de cuentas, cobro de cheques, etc.)
Retrasos en las operaciones.
Elevados tiempos de espera para los clientes.
Costes de personal innecesarios.
1.1. Justificación y aplicaciones
El reconocimiento de firmas se basa en la búsqueda en una base de datos aquélla que más se le parece, es decir, la que tenga mayor porcentaje de similitud. Sin embargo, la verificación decide si dos firmas son lo suficientemente parecidas como para suponer con un cierto grado de confianza que proceden del mismo autor.
La experiencia en entidades en las que ya se han realizado estudios, muestran que aproximadamente el 70% de las operaciones precisan de verificación [1]. En consecuencia, para realizar un estudio de ahorro/costes, sería suficiente conocer que la media ponderada del actual sistema manual de comprobación de firmas es de 1,5 minutos por firma, con un coste también aproximado de 0,24 minuto/empleado [1], comparado con los 0,3 segundos por firma mediante la utilización del software del proyecto. (Y posiblemente la ausencia de empleado). Si ha esto añadimos que por ejemplo, la banca francesa genera aproximadamente cinco mil millones de cheques y mil millones de depósitos al año, nos da una idea del enorme potencial de esta tecnología [2].
Parece evidente que debido a la importancia de los documentos, su valor y su repercusión en caso de fraude, los documentos bancarios serán los mayores beneficiarios de esta tecnología, aunque resultaría sencillo encontrarle otras aplicaciones, principalmente en el control de documentos oficiales, escrituras, contratos, etc. Así como en empresas para el control de gastos, partidas presupuestarias, en Universidades, Hacienda, Ministerios, incluso como sistema de seguridad biométrico, puesto que al igual que el iris, las huellas dactilares o la firma manuscrita permiten identificar a las personas, pudiéndose aplicar en controles de acceso a edificios, aeropuertos, etc. En definitiva, en todas las situaciones en las que se requiera verificar para contrastar la identidad.
1.2. Situación actual
En estos momentos y en el mejor de los casos, nos encontramos con un empleado de banca que puede consultar la firma patrón digitalizada en el servidor por medio de su aplicación de gestión y de esta manera el empleado o su supervisor procede a verificarlas, realizando una comparación manual.
Las técnicas de Visión Artificial, permiten abordar y resolver este tipo de problemas. Se trata de un área multidisciplinar en el que intervienen la Geometría, los Gráficos por ordenador, la Estadística, Procesado Digital de Imagen, etc. Su objetivo es reconocer los objetos que están representados en una imagen, y obtener información sobre ellos. En este sentido, es una disciplina complementaria a los Gráficos por Computador, donde el objetivo es producir una imagen que represente una serie de objetos a partir de una descripción de los mismos [3].
Las aplicaciones de la Visión Artificial son muchas y muy importantes, desde el reconocimiento automático de errores de fabricación en componentes al análisis de imágenes astronómicas o médicas. Como en otras disciplinas, el progreso es quizás más lento de lo que se esperaba, simplemente porque se desconocen los mecanismos que nos permite interpretar las imágenes.
Las imágenes de ordenador se pueden crear y almacenar en memoria de diversas maneras, aunque la representación raster es una de las más conocidas y es la que se utilizará para la realización de este trabajo. En este tipo de representación la imagen está formada por filas y columnas de puntos, es decir, es una matriz de píxeles, siendo un píxel un punto en la imagen; (el nombre píxel es una abreviatura de picture element, o elemento de la imagen). El formato de imagen que se va a utilizar es el BMP [4] (Formato estándar de imágenes de bitmap de los sistemas operativos de Microsoft e IBM OS/2).
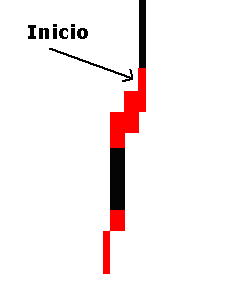
Figura 1. Diferentes ejemplos de firmas
Por otra parte para hacer un buen análisis sobre una firma es necesario comprender qué elementos son los más importantes para llevar a cabo la verificación. En este sentido nos remitimos a la grafología que gracias a los estudios forenses sobre documentos cuestionables ha logrado importantes avances en este campo.
En el momento de estudiar una firma nos podemos encontrar con firmas en las que aparece claramente el nombre completo, sólo el nombre o el apellido, las iniciales, la iniciales y el apellido o simplemente un trazo incomprensible. Generalmente viene acompañado de la rúbrica que es el gesto menos pensado de todos los que se realizan cuando se escribe. Es el trazo menos consciente y más ágil de la escritura, salvo que alguien lo haga con plena voluntad para corregir algún matiz particular de su personalidad (grafoterapia) o como demostración de una peculariedad de su profesión (caso frecuente en los artistas). La firma, al ser un elemento personal se ha utilizado y se utiliza para plasmar la identidad del autor, por ello la falsificación de la firma es uno de los métodos más habituales para suplantar a una persona, generalmente con un fin económico. Las falsificación de firmas se puede clasificar en dos clases:
- Las falsificaciones burdas: son las más frecuentes y son aquellas en las que el falsificador desconoce la firma original y por tanto las similitudes son pocas o casuales.
- Las falsificaciones expertas: son poco frecuentes y están realizadas por un falsificador con entrenamiento, el cual conoce la firma y la reproduce con cierta maestría.
Probablemente la pregunta que más se repite en grafología es ¿en qué hay que fijarse para realizar un examen grafológico? Y la respuesta en tan sencilla como en todo... y en nada, aspectos como el tamaño, las proporciones, la consistencia, la proximidad y respeto de la línea base, la presión, la densidad de escritura, la seguridad de los trazos, la alineación e inclinación son entre otros fundamentales para el estudio. Aún así, nada de lo anterior nos asegura nada, no hay evidencia sino la opinión de un experto, la cual se ha ido formando con el aprendizaje y la experiencia [5]. Todo lo anterior nos permite reflexionar sobre la complejidad de los problemas a los que nos enfrentamos.
1.3. Objetivos
El objetivo de este proyecto es la realización de un sistema software capaz de reconocer o rechazar dos firmas manuscritas como pertenecientes al mismo autor (verificación de firmas), así como, buscar en una base de datos aquella que más se asemeja a una dada (reconocimiento de una firma).
Los sistemas de reconocimiento de imágenes pueden llegar a ser muy lentos y complicados, por ello en este proyecto se seguirá una línea de trabajo que se caracterizará por la sencillez y la rapidez. El software desarrollado deberá satisfacer los siguientes requisitos:
1.3.1. Requisitos funcionales:
- Será capaz de decidir si dos firmas se asemejan lo suficientemente como para pertenecer al mismo autor.
- Se centrará en detectar las falsificaciones burdas, ya que son las que una persona sin un entrenamiento especial consigue diferenciar.
- Buscará en una base de datos de firmas, aquélla que más se parezca a la firma que se quiera reconocer.
1.3.2. Requisitos no funcionales:
- Se pretende que sea lo suficientemente rápido como para poder usarlo en tiempo real, y que pueda competir con una persona tanto en fiabilidad como en rapidez.
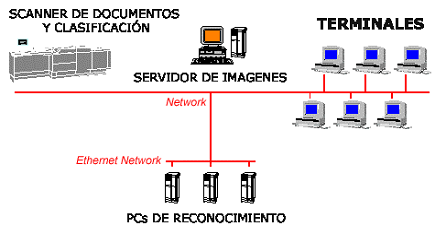
- Deberá necesitar poca memoria para facilitar su ejecución en paralelo, en los equipos de reconocimiento (Figura 5).
- Su diseño será modular. Cada etapa estará claramente diferenciada de la anterior, de tal manera que cada fase se pueda ejecutar en un equipo o procesador distinto.
- La firmas estarán digitalizadas con una resolución de 200ppp y en formato BMP [4].
1.4. Esquema propuesto de la solución
En los próximos capítulos se irán presentando los pasos que se han seguido, así como, las diversas variantes entre las que se puede elegir a la hora de resolver los problemas que surgen en cada etapa del proceso.
De forma resumida y simplificada la solución encontrada para el problema del reconocimiento y verificación de las firmas manuscritas obedece al siguiente esquema:
1. Esqueletizado de la imagen. Para ello se ha utilizando el algoritmo de Zhang y Suen [6].
2. Etiquetado de los trazos según su inclinación utilizando cuatro matrices de convolución de tamaño 2x2.
3. Seguimiento y extracción de los trazos. Utilizando un esquema de búsqueda con retroceso o backtracking.
4. Cálculo de la caja de Feret [7] del conjunto de los trazos.
5. Normalizado de los trazos respecto a la dimensión de la caja de Feret [7].
6. Comparación de los trazos de las dos imágenes mediante ajuste de distancias (distance matching) [8]
El resultado del sistema es un porcentaje de similitud entre las dos imágenes de entrada.
Diagrama de flujo:

Para el estudio del proyecto se han realizados dos aplicaciones:
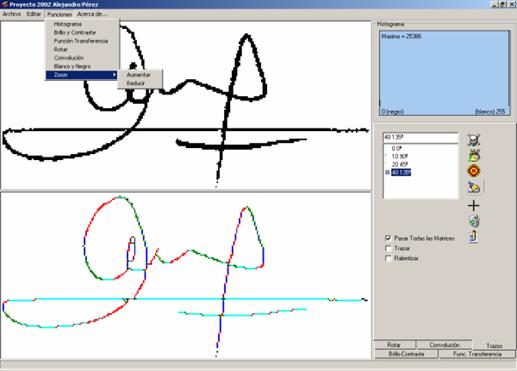
- La primera aplicación ha consistido en la implementación de varios filtros y procedimientos (esqueletizado, rotación, operaciones sobre el histograma, función de transferencia, operaciones con matrices de convolución, brillo, contraste, etc.) utilizándose para el estudio y viabilidad de cada fase, así como para verificar o corregir la implementación de los algoritmos.
Figura 2. Aplicación de investigación y pruebas
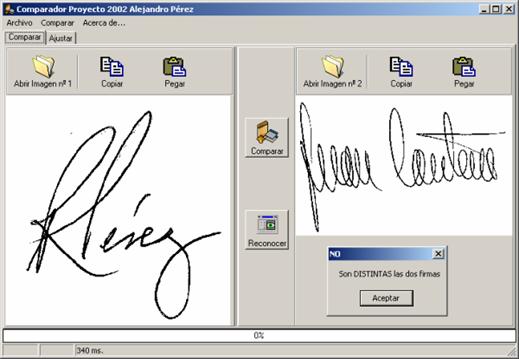
- La aplicación definitiva, en la que se ha implementado la verificación de firmas y el reconocimiento con la base de datos, la cual está formada por el directorio llamado bd con un patrón de cada clase a reconocer en formato bmp.
Figura 3. Aplicación definitiva. Verificación y reconocimiento de firmas
Todas las funciones gráficas se han implementado en una unidad independiente (Figura 4) para facilitar la reutilización del código, el lenguaje de programación elegido ha sido Object Pascal, utilizando el compilador de Borland Delphi 6.0 Professional.

Figura 4. Estructura del código del proyecto
La solución propuesta responde al esquema de la Figura 5 donde se puede verificar las firmas sin la necesidad de actuación de un humano, o por lo menos reducir esta participación a los casos dudosos con el consiguiente ahorro de costes, seguridad, tiempo y productividad.
Figura 5. Esquema propuesto de implantación del sistema
2. Fundamentos del reconocimiento de formas
2.1. Reconocimiento on-line y off-line
El reconocimiento on-line significa que el proceso se realiza mientras que el usuario está escribiendo por lo que es necesario emplear una tableta digitalizadora y un lápiz especial. Sin embargo permite contar además de con la firma original con algunos datos extras, como la presión, la velocidad, el punto de inicio y fin de los trazos, etc. [9].
Por el contrario, el reconocimiento off-line se realiza posteriormente, es decir, una vez que el usuario ha terminado de firmar. Por ejemplo, se puede escanear un documento con la firma y luego reconocerla. Sin embargo, no hay una separación clara en lo que se refiere a los algoritmos a emplear en cada uno de los dos casos. Un sistema on-line puede fácilmente usar algoritmos destinados a un sistema off-line simplemente convirtiendo la información a un bitmap. Por el contrario, también hay formas de extraer información de un mapa de bits e intentar adivinar cómo fue dibujado ese trazo [10] (con mayor o menor grado de acierto).
2.1.1. Ventajas e inconvenientes
Los dos grupos de métodos de reconocimiento de firmas presentan ventajas e inconvenientes. En el reconocimiento on-line se obtiene mucha más información. Se pueden obtener secuencias ordenadas de puntos agrupados en trazos simplemente fijándose cuándo el usuario apoya y levanta el lápiz, en comparación con el bitmap desordenado que se obtiene al escanear un documento [11].
Para cada punto se puede saber el momento exacto en el que se dibujó pudiéndose calcular características como la velocidad, la aceleración del lapicero (midiendo la distancia entre dos puntos escaneados en un periodo de tiempo fijo), incluso algunas tabletas permiten saber la presión y ver cómo varía a lo largo de la firma. Teniendo en cuenta que se recibe información inmediata del lápiz, cabe la posibilidad de aprender y ajustar el sistema de reconocimiento en tiempo real mejorando los índices de acierto, incluso el usuario puede enseñar al sistema cómo le gusta escribir ciertas letras o trazos.
Uno de los mayores inconvenientes de los sistemas on-line es que requieren el uso de material especial (tableta, lápiz, etc.) y la posibilidad de que varíen ciertas características ya que no es lo mismo escribir con un bolígrafo sobre papel que con uno de plástico sobre una pantalla táctil. En este tipo de sistemas es muy importante la velocidad de respuesta puesto que el usuario se encuentra esperando a que finalice el reconocimiento.
Por otra parte, al analizar una firma como imagen según un proceso off-line se tienen una serie de problemas típicos asociados al Reconocimiento Óptico de Caracteres (OCR), tales como la traslación (vertical y horizontal), la rotación, el problema de dimensionamiento, así como la menor cantidad de información, por mencionar sólo algunos. Sin embargo, presenta alguna ventaja como es la posibilidad de aplicarse sin la presencia del sujeto y resulta menos costoso a nivel de equipamiento.
2.2. Propiedades de la escritura manuscrita
La característica más importante de un alfabeto debe ser que las diferencias entre distintos caracteres son mayores que las diferencias entre diferentes muestras del mismo carácter incluso escritas por diversos autores. Pero hay casos en nuestro alfabeto que esto no es del todo cierto y por ejemplo las letra I ( i mayúscula) y la l (L minúscula) las diferenciamos más por el contexto en el que se encuentran que por su apariencia.
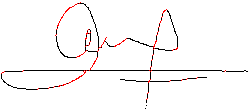
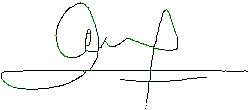
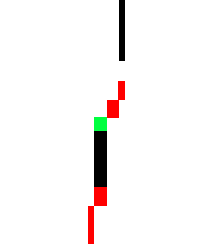
En el caso de las firmas, en muchas ocasiones ni nosotros mismos somos capaces de reconocer caracteres en ellas, simplemente vemos trazos, formas que nos dan información, pero no es una información clara ni exacta. De manera que, incluso dos firmas del mismo autor (Figura 6) pueden diferir en muchos detalles (Figura 7).
Figura 6. Firma patrón
Figura 7. Variación de la firma
Por tanto, parece obvio que uno de los objetivos será fijarse y centrarse en las formas más característicos y relevantes de la firma e intentar obviar los detalles menos significativos, o por lo menos no darles demasiada importancia.
2.3. Reconocimiento de Formas
2.3.1. Objetivos y enfoque
Para llevar a cabo un reconocimiento de formas es necesario realizar un modelado del proceso de razonamiento, además se debe tener en cuenta que existe una imposibilidad intrínseca de alcanzar resultados exactos.
El modelado del proceso de percepción es difícil de formalizar (es raro que un experto pueda verbalizar sus habilidades). Además requiere una extraordinaria plasticidad: aprendizaje (inconsciente) mediante exposición reiterada de los problemas a resolver (y de sus soluciones).
Para el procesamiento de la percepción existen dos posibles enfoques [12]:
- Inteligencia Artificial: Énfasis en el razonamiento, la lógica y la cognición.
- Reconocimiento de Formas: Énfasis en la percepción y el aprendizaje, aspectos simples del razonamiento.
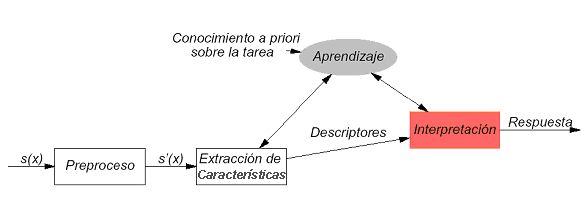
Este proyecto tiene un diseño y una estructura basado en el enfoque de los sistemas de reconocimiento de formas, con una fase de preproceso, una segunda de extracción de características y una interpretación de los resultados mediante un clasificador y un aprendizaje que dan lugar a la respuesta [36].
2.3.2. Diagrama de bloques de un sistema de reconocimiento de formas
Figura 8. Diagrama de bloques de un sistema de reconocimiento de formas
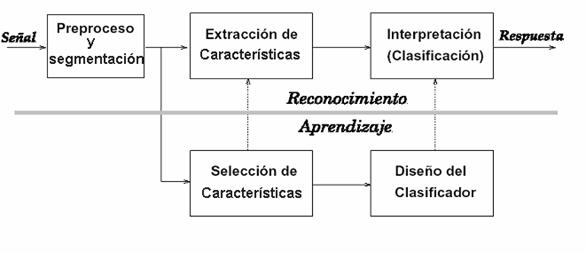
2.3.3. Diseño de un sistema de reconocimiento de formas
Figura 9. Diseño de un sistema de reconocimiento de formas
3. Preproceso
3.1. Etapas de preproceso de firmas
Dependiendo del algoritmo que se elija en la selección de características, en la elección del clasificador o en la interpretación de resultados puede ser necesario emplear distintos tipos de preproceso para incrementar el índice de fiabilidad o la velocidad de reconocimiento [13].
3.1.1. Limpieza y eliminación del ruido
Muchas veces al escanear un documento se introducen errores debido a manchas en el cristal, suciedad en el documento, etc. Estas manchas pueden introducir errores a la hora de interpretar la información. En este proyecto, al centrarnos en los trazos más significativos de la firma y desestimar los detalles, el pequeño ruido será obviado por la etapa de extracción de trazos, aunque un preproceso en este sentido serviría para incrementar el rendimiento en etapas posteriores.
La eliminación de ruido gaussiano o ruido uniforme, puede ser tratado con un filtro lineal, con una máscara determinada que elimine los píxeles solitarios o con un filtro no lineal como puede ser el filtro de la mediana que consiste en reemplazar el nivel de gris de cada píxel por la mediana de los valores de grises de los vecinos [14].
3.1.2. Esqueletizado
Dado que lo que se busca es la dirección y la forma que tiene la firma y no tanto sus pequeños detalles como las pequeñas manchas, signos de puntuación o el grosor del bolígrafo que además, es un factor que puede variar significativamente de una muestra a otra, parece razonable pensar que un adelgazamiento de la firma podría ser de gran ayuda.
La esqueletización o adelgazamiento es una técnica muy usada en el reconocimiento de patrones. Consiste en eliminar píxeles de la imagen hasta que queda un esqueleto de un píxel de grosor. Idealmente, este esqueleto contiene toda la información relevante de la región, conservando el mismo número de regiones de la imagen, y debe ser similar a la región original. Esto resulta complicado de conseguir y puede introducir ciertos artefactos de ruido no presentes en la firma original. De hecho, aunque ha habido muchos intentos de resolver el problema, no hay todavía una solución completamente satisfactoria.
La idea del algoritmo es que la esqueletización se puede ver como la eliminación de capa tras capa de píxeles de frontera, es decir, como erosiones repetidas, pero teniendo cuidado de no eliminar los píxeles que mantienen las relaciones de conexión. El algoritmo que se ha utilizado es el de Zhang y Suen [6] que supone que los píxeles del objeto están marcados como valor uno mientras que el resto están a cero. Los píxeles del contorno son aquellos etiquetados como uno, que tienen al menos uno de los ocho vecinos a cero [14] y [15].
Con referencia a la notación de la Figura 10, el procedimiento aplica los siguientes dos tests a los píxeles del contorno:
TEST1: un píxel del contorno se marca para borrado si cumple las siguientes cuatro condiciones:
(a) 2 <= N(p1) <= 6
(b) S(p1) = 1
(c) p2 * p4 * p6 = 0
(d) p4 * p6 * p8 = 0
donde N(p1) es el número de vecinos nulos de p1, en una 8-vecindad, es decir:
N(p1) = p2 +p3 + p4 + p5 + p6 +p7 +p8 + p9
y S(p1) es el número de transiciones 0-1 en la secuencia ordenada p2, p3, p4, p5, p6, p7, p8, p9
p9
p2
p3
p8
p1
p4
p7
p6
p5
Figura 10. Notación esqueletizado
0
0
1
1
p1
0
1
0
1
Figura 11. Ejemplo de transiciones
Por ejemplo, en el caso de la Figura 11, se tiene que N(p1) =4 y S(p1)=3
TEST2: se marcan para eliminar también los píxeles del contorno que verifican las siguientes cuatro propiedades:
(a) 2 <= N(p1) <= 6
(b) S(p1) = 1
(c) p2 * p4 * p8 = 0
(d) p2 * p6 * p8 = 0
Por tanto, cada iteración de este algoritmo queda esquematizada en el siguiente pseudocódigo:
1. Para todos los píxeles del contorno, marcarlo como candidato a ser borrado si cumple las cuatro condiciones del Test1
2. Una vez recorridos todos los puntos borrar (poner a 0) todos los píxeles marcados en el paso anterior.
3. Para todos los píxeles del contorno, marcarlo como candidato a ser borrado si cumple las cuatro condiciones del Test2
4. Una vez recorridos todos los puntos borrar (poner a 0) todos los píxeles marcados en el test 2.
5. Volver al paso 1 mientras se sigan marcando píxeles.
Figura 12. Original esqueletizado
Figura 13. Resultado esqueletizado
En la Figura 12 podemos observar el efecto del ruido y el resultado de la operación de esqueletizado de Zhang y Suen [6] en la Figura 13. Comprobamos que la información de los trazos se mantiene y que la distorsión producida por el ruido se reduce o por lo menos no introduce mucho error en los trazos o no más que las variaciones que pudiera introducir el autor en posteriores firmas. Por este motivo el sistema del proyecto es resistente al ruido moderado.
3.2. Técnicas de etiquetado de trazos
El siguiente paso consistirá en detectar los píxeles que forman los trazos, y etiquetarlos según la inclinación del trazo, de esta manera se conseguirá extraer los trazos verticales, horizontales, etc. Existen distintas manera de abordar este problema [16].
3.2.1. Redes de neuronas
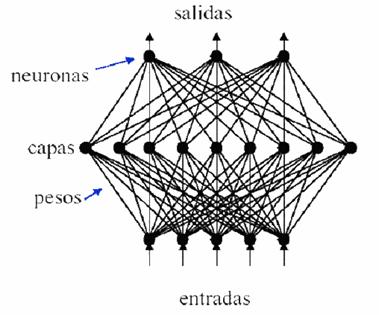
Se ha avanzado mucho en el estudio de las redes de neuronas y su aplicación al reconocimiento de patrones. Las Redes de Neuronas Artificiales (ANN o NN) son usadas como reconocedores independientes o como parte integrada en otro algoritmo. El funcionamiento de las Redes de Neuronas Artificiales tiene su base en la interacción de unos elementos, las células nerviosas o neuronas, a través de unas conexiones llamadas conexiones sinápticas. Tales conexiones tienen su origen en una neurona (a la que se denomina neurona de salida) y su destino en otra neurona (a la que se llama neurona de entrada). Estas conexiones tienen asociado un peso que es un valor real variable que determina la influencia de la misma (Figura 14).
Figura 14. Esquema de una red de neurona
Una misma neurona puede ser destino de varias conexiones sinápticas. Por ello, las entradas que una neurona recibe se procesan, mediante la función de activación, para definir el estado de activación de la célula nerviosa. A partir de la función de activación se genera la salida de la neurona mediante la función de salida [17].
Hay muchos tipos de redes de neuronas artificiales [18] (Figura 14) dependiendo de si sus señales son analógicas o binarias, si el tipo de aprendizaje es supervisado o no supervisado o según la funcionalidad a la que están dirigidas, a la clasificación, memoria u optimización [19].
3.2.2. Perceptrón multicapa
Estudios de la zona del cortex dedicada a la visión han detectado que hay ciertas neuronas o grupos de neuronas especializadas en reconocer ciertos tipos de formas como por ejemplo una línea recta en una cierta dirección. Estas neuronas están organizadas de una forma geométrica de tal modo que cada neurona tiene un receptor local y únicamente se activará cuando reciba la línea recta en una cierta dirección por su receptor [37]
Estos tipos de conexiones entre neuronas han sido simuladas con grandes perceptrones multicapas usando el algoritmo de aprendizaje back propagation [20] y [21]. Se trata de uno de los modelos de aprendizaje supervisado que más se implementa actualmente no sólo porque es el mejor modelo de propósito general y, probablemente, el que mejor generaliza las respuestas. Sino también, porque proporciona una explicación matemática a la dinámica del proceso de aprendizaje.
Este tipo de asociación de neuronas tiene una series de ventajas y características [17]:
1. Robustez frente al ruido aleatorio. Lo que conlleva la selección automática de las características importantes dentro del vector de características que es entrada a la red.
2. Separación de regiones complejas dependiendo de la estructura de la red. Una red puede separar clases a pesar de que la hipersuperficie de separación entre ambas sea arbitrariamente compleja, o incluso no sea única.
3. Capacidad de generalización. Los algoritmos de descenso del gradiente han demostrado con la práctica que obtienen buenas interpolaciones para patrones con los que no se ha entrenado al sistema.
Sin embargo, el esfuerzo de cómputo que requiere este método hace que no sea practicable en mucho casos.
Hay dos tipos de modelos de aprendizaje para las redes de neuronas: supervisado y no supervisado. El aprendizaje supervisado es la forma más elemental de adaptación. Requiere un conocimiento a priori de las respuestas correctas. Durante el entrenamiento, la salida de la red se compara con la respuesta ideal y el error que exista se utiliza para corregir la red. El aprendizaje se produce como resultado de cambiar los pesos para reducir el error. Es similar al proceso de adquirir experiencia.
El aprendizaje no-supervisado se diferencia del anterior en que no se hace una corrección específica comparando los resultados obtenidos con la solución ideal esperada. El sistema básico está formado por una matriz de una o dos dimensiones de unidades lógicas con umbral, con un rango de conexiones laterales con las neuronas vecinas. El sistema se modifica a sí mismo con el objeto de que las neuronas cercanas respondan de una forma similar. Esta modificación es una competición entre todas las neuronas.
En este modelo, no sólo se ajustan los pesos de la neurona ganadora, sino que también se ajustan los pesos de las neuronas vecinas. Aunque en este proyecto no se ha utilizado ningún tipo específico de redes de neuronas, sí que el sistema ha requerido de un aprendizaje supervisado como ya veremos más adelante.
3.2.3. Modular networks
Hay otro tipo de aproximaciones e intentos de simular la actividad de las neuronas del cortex visual. Una de las aproximaciones es disponer de un mapa autoorganizado [22] (llamado mapa de Kohonen, ver Figura 15, que es uno de los modelos más populares de aprendizaje no-supervisado) y entrenarlo con ejemplos de firmas o letras manuscritas. La salida del SOM (Self Organizing Map) puede ser redirigida a la entrada de otro clasificador neuronal [21], por ejemplo un perceptrón o un perceptrón multicapa, y crear de esa forma lo que se llama una modular network [24]. Otro tipo de aproximación es una un red del tipo Hopfield para producir un mapa de actividad [25].
Figura 15. Mapa de Kohonen
En la Figura 15 los pesos de un mapa de Kohonen al que ha sido presentado las letras desde la A hasta la Z. Se puede observar por ejemplo, como las neuronas de la parte inferior derecha son más sensibles a letras similares a la C.
3.2.4. Matrices de convolución
Las matrices de convolución permiten realizar en el dominio del espacio filtrados en el que el resultado de un píxel después de aplicarle una función que se conoce como impulsional depende únicamente de su valor y del de sus vecinos [17].
De esta manera, suponiendo la siguiente función impulsional h de tamaño 3x3 igual a la matriz que sigue:
h=
La imagen de salida I resultante de aplicar el filtrado espacial viene dada por la expresión:
I(x,y) = I(x,y)*h = h1 I(x-1, y-1) + h2 I(x, y-1) + h3 I(x+1, y-1) +
h4 I(x-1, y) + h5 I(x,y) + h6 I(x+1, y) +
h7 I(x-1, y+1) + h8 I(x, y+1) + h9 I(x+1, y+1)
Si no se hubiera esqueletizado como etapa de preproceso en el análisis de la firma, habría que ir añadiendo matrices de convolución de por ejemplo 9X9 para ir detectando los trazos de distinto grosor, e inclinación. Por ejemplo aplicando la siguiente matriz de 9X9 se detectarían los trazos de una inclinación de aprox. 120º (Figura 16).
Figura 16. Matriz de convolución aplicada
Gracias a que ya se ha esqueletizado se puede reducir el problema a pasar por la imagen de origen cuatro matrices de convolución de 2X2 con las cuatro direcciones:
1
1
0
0
1
0
1
0
1
0
0
1
0
1
1
0
Obteniendo las siguientes cuatro salidas:
Como se puede apreciar, un mismo píxel puede haber sido etiquetado con cuatro inclinaciones distintas, es decir un mismo píxel puede formar parte de varios trazos. Esto es interesante en el caso de los cruces de trazos, pues evita pérdida de información.
Otro hecho importante en este proceso es que se produce una simplificación y por tanto una pérdida de información respecto al original, ya que los trazos se han aproximado a rectas de 0º, 45º, 90º y 135º. Esto podría suponer aparentemente un inconveniente, sin embargo, será precisamente este hecho el que nos permita decir que dos trazos de distintas firmas de la misma persona sean iguales a pesar de que sean ligeramente diferentes.
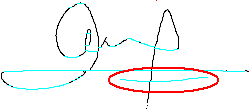
Por ejemplo, en el caso de aplicar la matriz de convolución 0º sobre la firma original, podemos apreciar en la Figura 27 que el subrayado está etiquetado como una línea horizontal y sin embargo presenta una cierta curvatura.
Figura 27. Aproximación realizada
Lo peculiar de la aproximación, es que aunque en otras firmas del mismo autor este subrayado sea más horizontal o ligeramente más curvo (hasta los bº siendo bº = 22,5º - aº donde a es la inclinación del trazo original) seguirá siendo etiquetado como trazo horizontal, lo que proporciona una gran flexibilidad ante pequeñas variaciones de los trazos. De esta forma se consigue que si se tienen como entradas dos firmas iguales de la misma persona y una de ellas tenga una ligera inclinación respecto a la otra, el sistema seguirá clasificándolas de igual manera, sin necesidad de tener que rotarlas respecto a su eje de inercia. Lo que otorga una cierta robustez frente a pequeñas inclinaciones, típicas del proceso de adquisición de imágenes y respecto a las variaciones de los trazos habituales en la escritura manuscrita.
Comparar con Figura 23. Resultado matriz 0º
Comparar con Figura 24. Resultado matriz 90º
4. Extracción de características
4.1. Introducción
Las características que se buscan son los trazos que hay en la firma con una orientación de 0º, 45º, 90º y 135º. Para ello y una vez que ya tenemos los píxeles etiquetados con su orientación debemos hacer un proceso de seguimiento y extracción de los segmentos de color de los ejemplos anteriores. A continuación, se introducen los conceptos de conectividad 4 y 8, que son necesarios para este trabajo.
4.2. 8-vecinos y relaciones de proximidad
Un camino de vecinos es una secuencia de píxeles que se puede recorrer completamente saltando de un píxel a su vecino, y al vecino de éste hasta el final. Por tanto, existen dos posibles definiciones de región conexa, según el tipo de relación de vecindad que se establezca.
Una región 4-conexa es un conjunto de píxeles del mismo color, en que cualquier par de píxeles puede ser unido mediante un camino de 4-vecinos pertenecientes a la región. La definición de región 8-conexa es análoga, pero teniendo en cuenta a los 8 vecinos de un píxel dado (Figura 29) [26].
Figura 29. Relaciones de vecindad
Más adelante veremos cómo las regiones 8-conexas son más adecuadas para este estudio.
4.3. Algoritmo de seguimiento y extracción de trazos
El algoritmo propuesto es similar al de la extracción de las componentes conexas de una imagen aunque lo modificaremos para nuestro caso particular.
Para todo píxel p de una imagen, el conjunto de los píxeles hasta los que hay un camino desde p se dice que forman su componente conexa. Además se cumple que dos componentes conexas distintas tienen conjuntos de píxeles disjuntos.
Un algoritmo de este tipo se puede construir fácilmente usando un esquema recursivo de búsqueda con retroceso. Tal algoritmo recorre la imagen de izquierda a derecha y de arriba abajo. Cuando encuentra un píxel a negro le asigna una etiqueta de un contador que posee y entra en una función recursiva que recorre los píxeles adyacentes, siguiendo un orden preestablecido, marcándolos como visitados y asignándoles el mismo valor del contador. Una vez recorridos todos los píxeles de ese objeto incrementa el contador y sigue recorriendo la imagen en busca del siguiente píxel a negro [17].
El algoritmo anterior no es eficiente por dos motivos:
- Se puede llegar a preguntar varias veces por cada píxel de la imagen. Cuando se encuentra el primer píxel de un objeto se visitan los puntos de ese objeto, puntos por los que luego se va a volver a preguntar, aunque ya han sido visitados.
- El uso de la recursividad no es recomendable cuando el número de llamadas recursivas va a ser grande. Una llamada recursiva a una función implica la copia del estado del sistema y la asignación de nuevas variables, siendo en general poco eficiente en cuanto a tiempo y memoria. Realizar este tipo de operaciones por cada píxel de una imagen puede implicar varios millones de llamadas a función, lo que termina generalmente con un error por falta de memoria y en el mejor de los casos en una implementación lenta.
En el caso del proyecto estos problemas se resuelven usando un doble bucle para recorrer la imagen de arriba abajo y de izquierda a derecha. Cuando encuentra un píxel etiquetado del color que queremos extraer el trazo mira a sus vecinos en un determinado orden, que veremos a continuación, y los sigue hasta completar ese trazo, marcándolos como visitados, al finalizar el trazo, continua en el punto en el que se había quedado. De esta manera se soluciona el problema de la recursividad y de visitar varias veces el mismo píxel.
Al haber empleado cuatro matrices de convolución, una por cada inclinación, hay que aplicar también cuatro veces el algoritmo de seguimiento y extracción de los trazos con la ayuda de los colores. Por lo tanto tenemos una imagen con el fondo en blanco, los píxeles de la firma en negro y los píxeles de la firma que forman parte de un trazo con la inclinación adecuada de color.
4.3.1. Seguimiento de trazos sensible a píxeles sin etiquetar
Al realizar la convolución puede ocurrir que queden píxeles sin etiquetar (en negro) sin embargo, el objetivo es extraer el trazo completo como un solo elemento de longitud igual al segmento de color azul en la Figura 30 y no como una serie de pequeños trazos rojos (45º).
Figura 30. Ejemplo píxeles sin etiquetar
Figura 31. Resultado seguimiento sensible a píxeles sin etiquetar
Para solucionarlo, el algoritmo comenzará por un píxel rojo y lo seguirá hasta encontrarse con uno negro, seguirá el negro hasta una distancia prudencial que llamaremos horizonte (por ejemplo 6 píxeles), en ese caso, si encuentra un píxel a rojo, etiquetará los anteriores píxeles negros a rojos y continuará. En caso de no encontrar ningún píxel rojo, parará y extraerá el trazo hasta el último píxel rojo encontrado, marcando como visitados los anteriores puntos para no volver a visitarlos en posteriores iteraciones, optimizando de esta manera el algoritmo recursivo descrito en el punto anterior, consiguiendo de esta forma una complejidad O(n) siendo n el número de píxeles de la firma.
4.3.2. Prioridad en las transiciones
Con referencia a la notación de la Figura 32, que codifica la tabla de direcciones, el algoritmo de seguimiento no permite o da prioridad a aquellas transiciones que más interese en cada situación. Por ejemplo, para los trazos de 45º (color rojo) las transiciones prioritarias tanto cuando se esté leyendo píxeles rojos como cuando se esté saltando píxeles negros y teniendo presente que el algoritmo siempre recorre la imagen de arriba a abajo y de izquierda a derecha, el orden a seguir es:
{SW, W, S, SE, NW, E, N, NE}
NW
N
NE
W
E
SW
S
SE
Figura 32. Tabla de direcciones
La tabla completa de prioridades en el seguimiento del trazo es:
Pendiente
Color
Orientación
Secuencia de búsqueda
0º
Agua
W
{W, SW, NW, N, S, NE, SE, E}
0º
Agua
E
{E, NE, SE, N, S, SW, NW, W}
45º
Rojo
SW
{SW, W, S, SE, NW, E, N}
90º
Azul
S
{S, SE, SW, E, W, NE, NW, N}
135º
Verde
SE
{SE, E, S, SW, NE, W, N}
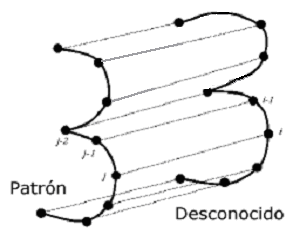
Para cada inclinación tenemos un caso, salvo para los 0º que puede darse la situación que se recorra el trazo de izquierda a derecha (en dirección E) o de derecha a izquierda (dirección W). Por lo tanto la tabla completa de prioridad de transiciones viene determinada por la inclinación (el color a seguir) y por la dirección en la que se espera encontrar el siguiente píxel del trazo.
Para la pendiente 0º comenzamos por ejemplo con la orientación W, si el siguiente píxel de color que se encuentra está en la posición E, significa que el trazo es de izquierda a derecha, ya que el único píxel de color que es vecino del actual está en la dirección opuesta. En consecuencia, para buscar el siguiente píxel se cambiará a orientación E y viceversa.
Otro detalle a destacar es que tanto la pendiente 45º como la de 135º deja por visitar una orientación, en concreto, la opuesta de la buscada, para 45º la orientación NE y para 135º la orientación NW. Esto es debido a que puede darse el siguiente caso:
Figura 33. Ejemplo de seguimiento
Figura 34. Posible error
Si partimos de la Figura 33 y aplicamos la secuencia de búsqueda apropiada para 45º (color rojo) obtenemos como resultado la Figura 34 y nos encontramos en el píxel verde, si la secuencia terminara buscando un píxel rojo en la dirección opuesta a la SW, es decir en la NE, lo encontraría y comenzaría a subir el algoritmo, en lugar de seguir bajando por los negros, encontrándose en un callejón sin salida y por tanto con el final del trazo. Para evitar que el algoritmo se detenga, en estos casos particulares, debido al esqueletizado de los segmentos inclinados, eliminamos de la secuencia de búsqueda la orientación opuesta de la que se busca.
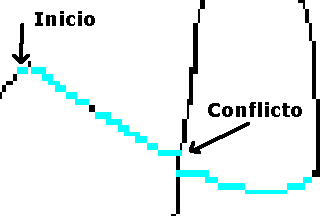
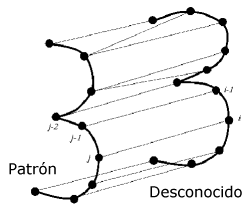
4.3.3. Búsqueda con retroceso
Otro elemento a tener en cuenta, es la necesidad de buscar el camino adecuado en los cruces de los trazos, debido principalmente a la distorsión producida en el proceso de esqueletizado (Figura 35).
Figura 35. Búsqueda con retroceso
En este caso, a pesar de ser el mismo trazo, el algoritmo del esqueletizado ha producido un escalonamiento en el cruce. Para solucionarlo se puede recurrir a un esquema de búsqueda con retroceso sobre los diferentes caminos posibles, en este caso, hacia arriba y hacia abajo.
Descripción
En cada iteración sólo se considera un sucesor, e igualmente se eliminan los nodos que sean una vía muerta. Cuanto mejor sea el criterio utilizado para limitar el número de estados considerados, más eficiente será el proceso de búsqueda, por eso se ha creado la tabla de transiciones [27].
Procedimiento
- Crear una lista de nodos llamada abierta e inicializarla con un único nodo raíz, al que se le asigna el estado inicial del problema planteado.
- Hasta que se encuentre una meta o se devuelva fallo realizar las siguientes acciones:
(1) Si abierta está vacía, terminar con fallo; en caso contrario continuar.
(2) Seleccionar el primer nodo de abierta y denominarlo m.
(3) Si la profundidad de m es igual a lp o si m ya no tiene más sucesores posibles, eliminarlo de abierta y regresar a 2; en caso contrario, continuar.
(4) Generar un nuevo sucesor m de m e introducirlo al principio de abierta, creando un puntero a m, y señalar que dicha rama ya ha sido considerada.
(4.1) si m es meta, abandonar el proceso iterativo iniciado en 2 devolviendo el camino de la solución, que se obtiene recorriendo los punteros de sus antepasados.
(4.2) si m se encuentra en un callejón sin salida eliminarlo de abierta y se continua el proceso iterativo en el paso 2.
Complejidad
Temporal: El número de operaciones para un factor de ramificación n y para una solución situada en el nivel p es del orden de O(n)p. En este caso y al estar esqueletizada la firma el factor de ramificación siempre será menor o igual que 8 por lo tanto n £ 8
Espacial: Basta con recordar el camino recorrido hasta un momento dado. Entonces, la complejidad es del orden de O(p).
Ventajas
Necesita muy poco espacio de almacenamiento y no se generan las ramas del árbol de búsqueda que se encuentren después del camino de la solución.
Desventajas
Saber cuál es lp y no establecer ningún orden previo recorrido de los sucesores de un nodo (la eficiencia temporal del método queda limitada por su carácter fortuito).
4.4. Codificación de los trazos
Para representar el tipo de datos trazo se puede utilizar por ejemplo un registro con los siguientes campos:
color: Integer
origen: TPoint
destino: TPoint
Figura 36. Tipo de datos TipoTrazo
x: Integer
y: Integer
Figura 37. Tipo de datos TPoint
Donde color representa la inclinación de trazo, origen el punto más alto del trazo y destino el punto más bajo del trazo, de esta forma los trazos de la firma se encuentran ordenados de izquierda a derecha y de arriba abajo, característica que facilitará la fase de comparación y su complejidad en tiempo.
Como indica la Figura 37, cada punto se representa mediante la coordenada x y la coordenada y.
Por lo tanto, al llegar a este punto del algoritmo se dispone de una lista de elementos del TipoTrazo (Figura 36), ordenada por colores, es decir, por las pendientes de los trazos y dentro de cada color por su posición absoluta, de izquierda a derecha y de arriba a abajo
4.5. Cálculo de la caja de Feret
A partir de este momento se comienza a trabajar directamente con la lista de trazos y no con la representación gráfica de la firma. De esta manera, ya no es necesario recorrer la imagen píxel a píxel, mejorando el rendimiento y reduciendo la complejidad que ya no será factor de n siendo n el número de píxeles de la firma como hasta ahora, sino que la complejidad de las próximas operaciones será función de n siendo n el número de trazos localizados, en el caso de este punto, referente al cálculo de la dimensión total del conjunto de los trazos caja de Feret [7], la complejidad es O(n).
El siguiente paso en el algoritmo es el cálculo de la caja de Feret (Feret Box), que se define como el rectángulo que circunscribe al conjunto de los trazos alineado respecto a los ejes cartesianos. Para calcularlo, es necesario recorrer los n trazos de la firma y almacenar las coordenadas de aquellos que tengan como origen o destino la mayor y menor X, y la mayor y menor Y (Figura 39). Al realizar este proceso sobre los trazos de la firma se consigue que las pequeñas manchas o el ruido no afecten a los siguientes procesos de escalado y normalización.
Una representación gráfica del proceso hasta este momento:
Figura 39. Caja de Feret sobre los trazos
4.6. Normalización de los trazos
El rectángulo negro de la Figura 39 delimita la dimensión útil de la firma, y respecto a estas dimensiones se realiza un proceso de normalización. De esta forma se consigue que los trazos sean independientes a las dimensiones iniciales de la firma, incluso cuando se producen deformaciones de estiramiento.
El proceso de normalización es el siguiente:
Se llamará x a la base del rectángulo negro de la Figura 39 e y a la altura del mismo rectángulo, p1 representará al punto superior izquierdo del rectángulo y p2 al inferior derecho.
Entonces:
Por tanto la complejidad de la normalización de los trazos es también O(n). Gráficamente lo que se ha conseguido hasta el momento es:
Figura 41. Extracción de los trazos y cálculo de la caja de Feret
5. Reconocimiento basado en trazos
5.1. Introducción
Como resultado de las etapas anteriores, las firmas se describen ahora mediante una lista de sus trazos que son independientes al tamaño original de la firma y al grosor del bolígrafo utilizado.
Un clasificador es un sistema que plantea el problema del reconocimiento como la asignación de los objetos, denominados patrones, a algunos de los grupos representativos, o clases, considerados en el problema. Cada clase representa, por tanto, un tipo diferente de objeto.
En este capítulo se describirá el proceso de comparación entre dos firmas y cómo un sencillo clasificador euclídeo permitirá obtener buenos resultados.
Para resolver el problema de comparar dos conjuntos de trazos y poder extraer algún tipo de medida que permita su posterior interpretación, se pueden utilizar varias técnicas usuales en el reconocimiento de caracteres manuscritos, que se exponen a continuación [24].
5.2. Ajuste de curvas (curve matching)
5.2.1. Ajuste de distancias (distance matching)
Este método consiste, en normalizar el tamaño de los trazos de las dos imágenes a comparar, seleccionar ciertos puntos de control a una distancia normalizada para obtener un trazo con un determinado número de puntos significativos y calcular la suma de las distancias entre los puntos correspondientes de las dos imágenes [28] y [29] (ver Figura 43).
Figura 43. Ajuste de distancias (distance matchig)
El principal inconveniente de este método es que no es muy robusto a las transformaciones del patrón y la solución suele estar fuertemente asociada a las características de escritura de un solo usuario. Aunque precisamente, este inconveniente en el reconocimiento de caracteres puede ser de gran ayuda en el reconocimiento de firmas, ya que es un problema con una fuerte dependencia con la caligrafía de cada sujeto [30] y [31].
5.2.2. Ajuste elástico (elastic matching)
La expresión ajuste elástico o elastic matching suele usarse habitualmente en el reconocimiento de escritura manuscrita para describir el método anterior pero en el que la comparación se realiza de una manera más dinámica.
Un método de ajuste de curvas (curve matching), conocido como ajuste elástico (elastic matching), utiliza como medida, la distancia entre puntos del patrón o la plantilla con los puntos de la imagen a comparar. La elección de los puntos que corresponden con la plantilla se realiza de forma dinámica y no estática como en el método anterior, eligiéndose el punto que se encuentra a menor distancia de uno dado de la otra [32] (Figura 44).
Figura 44. Ajuste elástico (elastic matching)
No hay necesidad de tener exactamente el mismo número de puntos en la plantilla que en la imagen a reconocer, los puntos redundantes son eliminados mediante un algoritmo de comparación. Aunque el método no está limitado a un número fijo de puntos en cada trazo, se suele realizar una normalización de la distancia entre puntos para reducir la redundancia y el tiempo de reconocimiento [33].
5.3. Combinación de clasificadores
También existe la posibilidad de combinar diferentes clasificadores para producir un clasificador más estable y robusto. Diferentes clasificadores se complementan y producen uno más completo, algunos son más tolerantes a la traslación, otros a la rotación y otros a distintos estilos de escritura.
Para combinar varios clasificadores hay que utilizar algún tipo de ponderación, darle diferentes pesos a los resultados obtenidos por cada uno de ellos [35].
Otra aproximación sería enviar la salida de los diferentes clasificadores a una red de neuronas para que tomara la decisión final. El principal inconveniente de la combinación de clasificadores es su coste computacional [28].
5.4. Algoritmo elegido
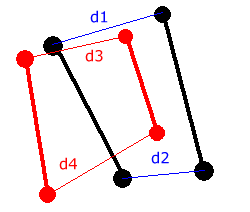
El algoritmo elegido es una modificación de los sistemas de ajuste de distancias (distance matching) aprovechando las simplificaciones realizadas hasta el momento. En especial, cada trazo curvo se ha aproximado a una recta, es decir, se puede representar por su punto de inicio y de fin y por la pendiente del trazo original (no de la recta que lo representa), por eso mantenemos la información del color que hace referencia a la inclinación de los trazos antes de la normalización.
Figura 45. Ajuste basado en las distancias
De esta manera, tenemos que hacer un ajuste o matching únicamente entre los dos puntos de referencia de la plantilla o patrón con los dos puntos del elemento a identificar.
Por tanto, puede decidirse que un trazo está en la plantilla (firma con la que se compara) cuando existe un trazo de ese mismo color cuya distancia d3 y d4 (Figura 45) es menor a una distancia D que se determinará de forma empírica.
Puede suceder que si se compara un patrón de por ejemplo 30 trazos con una firma muy compleja de 200 trazos, la posibilidad de encontrar un trazo a una distancia D del patrón es muy grande, por eso parece lógico pensar que si dos firman tienen un número de trazos muy distintos (se ha elegido un margen de error de 10 trazos de diferencia) representarán firmas distintas, no haciendo necesario el ajuste de los trazos. Esto es necesario porque en el proceso de adquisición de la imagen, en la transformación de los niveles de gris a blanco y negro o simplemente a la hora de firmar, hay trazos que se pierden, bien porque se hagan más cortos, con menor presión o que se superpongan con otros.
El algoritmo obedece al siguiente pseudocódigo:
1. Si el número de trazos de la imagen a reconocer es igual al número de trazos de la plantilla ± 10 pasar al paso 2, en otro caso el resultado (% similitud) = 0.0%
2. Para todo trazo de la plantilla, buscamos en la imagen a reconocer un trazo de ese mismo color (misma pendiente).
3. Si la distancia de sus extremos d3 y d4 (Figura 45) es menor a la distancia D determinada a-priori, eliminamos ese trazo de la imagen a reconocer para evitar que de un segundo positivo con otro trazo del patrón e incrementamos el valor de una variable llamada aciertos.
De esta manera, se puede calcular con muy poco esfuerzo de cómputo, el porcentaje de los trazos de la plantilla que tienen su pareja correspondiente en la imagen a reconocer. Cuanto mayor sea ese porcentaje de trazos encontrados significará que más parecidas son esas dos imágenes.
Resultado (% similitud) =
5.5. Determinación de los parámetros: longitud de trazo (LT), distancia de ajuste (D) y umbral de verificación (UV).
Hasta el momento nos hemos encontrado con tres variables importantes cuyo valor habrá que determinar empíricamente en un proceso de aprendizaje.
Una de ellas, es la longitud mínima de los trazos (LT) que se considerarán significativos, necesario para evitar que el ruido o pequeñas modificaciones de la firma afecten en el resultado de la caracterización. La segunda variable a determinar es la distancia (D) en el proceso de ajuste o matching y el tercer parámetro (UV) es necesario para el proceso de verificación de firmas, que consiste en comparar dos muestras y decidir con un cierto grado de confianza si pertenecen a la misma persona o no, de esta manera si se comparan dos firmas y se obtiene un índice de similitud superior a un cierto umbral (UV) se puede decir que son del mismo autor.
5.6. Proceso de aprendizaje
Para encontrar la pareja de valores que hacen óptimo el reconocimiento y la verificación, se ha utilizado una base de datos de 20 firmas pertenecientes a 10 personas, agrupadas de dos en dos, es decir 2 firmas del sujeto 1, 2 firmas del sujeto 2, etc. (Ver Figura 48 en el Apéndice).
Se ha implementado un doble bucle para probar cada pareja de valores.
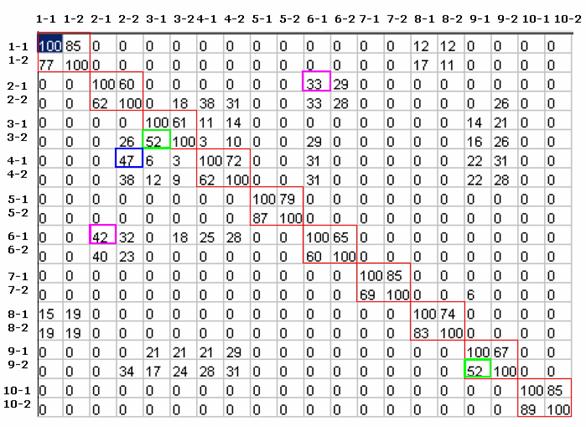
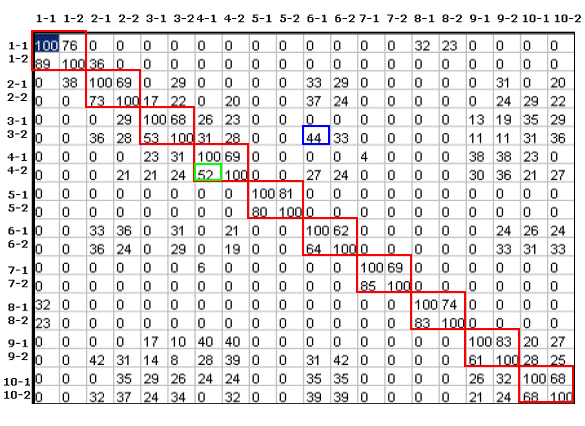
La pareja de valores de LT y D es solución si consigue que los valores de la diagonal (en rojo en la Figura 46) sean los mayores de la fila, lo que significa que al comparar dos firmas de la misma persona, no hay ninguna firma de otra persona que se parezca más al parecido que hay entre ellas. De esta manera nos aseguramos la funcionalidad del reconocimiento de firmas que consiste en la búsqueda en una base de datos aquella que más se parece a una dada.
Al realizar las 2.500 tablas (50X50) con sus respectiva 400 comparaciones (20x20) se almacenaron únicamente las combinaciones de valores de LT y D que cumplían con la condición anterior, obteniéndose una veintena de soluciones. Entre ellas se ha elegido aquella (Figura 46) que permite separar linealmente las clases, es decir, que el peor índice de similitud entre firmas de la misma persona (3-1 y la 3-2; 9-1 y la 9-2 un 52% en verde en la Figura 46) es mayor que el mayor índice de similitud entre firmas de distintas personas (2-2 y la 4-1 con un 47% en azul en la Figura 46). De esta forma con un sencillo clasificador euclídeo se puede disponer de la funcionalidad de la verificación de firmas fijando el umbral de verificación UV=51% de esta manera, si se comparan dos firmas y se obtiene un índice de similitud superior al 51% se puede decir que son de la misma persona.
Se ha generado la siguiente tabla de comparaciones para cada pareja de valores LT y D: (en este caso LT=15 y D=19 píxeles)
Patrones
Firmas a comparar
Figura 46. Tabla de aprendizaje
En la notación empleada en la Figura 46 (1-1, 1-2, 2-1, 2-2, etc.) el primer dígito hace referencia al propietario de la firma, y el segundo a la muestra o versión de esa firma. Por lo tanto, en la primera fila se ha comparado cada una de las firmas con la primera firma del usuario número 1.
Como se puede apreciar en rosa en la Figura 46, no es lo mismo comparar la firma 2-1 con la 6-1 (un 42%) que la firma 6-1 con la 2-1 (un 33%).
Por lo tanto, la solución encontrada en el proceso de aprendizaje es: para el umbral de verificación de firmas UV=51%, un valor para la longitud de trazo LT=15 píxeles mínimo y una distancia de ajuste D=20 píxeles. Al estar las firmas escaneadas a una resolución de 200ppp la longitud mínima de los trazos significativos es de:
De esta forma se ha conseguido asociar una función discriminante que da un valor máximo para cada una de las 10 clases probadas, este algoritmo se denomina descenso de gradiente [17], pues mejora sucesivamente la respuesta al problema hasta alcanzar una solución (generalmente no óptima). Este procedimiento de mejora sucesiva se denomina aprendizaje. En un instante cualquiera se tiene una función discriminante que comete un cierto error al comparar dos firmas. El algoritmo de aprendizaje se encarga de cambiar los valores de los parámetros de la función discriminantes en nuestro caso LT (longitud de trazo) y D (distancia de ajuste) para que se reduzca el error que se comete. Este proceso se repite iterativamente hasta encontrar unos valores aceptables.
El error cometido depende de lo que se quiere obtener (el patrón clasificado de acuerdo a lo que fija el maestro) y lo que se obtiene con las funciones discriminantes en su estado actual.
Error = diferencia entre lo que se desea obtener y lo que se obtiene
La diferencia con los reconocedores apriorísticos (sin aprendizaje) consiste en que en aquellos se calculaba a priori las funciones discriminantes, mientras que en éstos, las funciones discriminantes se calculan mediante un procedimiento iterativo (Figura 9).
6. Resultados de validación
Para validar el sistema se ha creado otro grupo de otras 20 firmas correspondientes a 10 personas agrupadas de dos en dos, al igual que en el ejercicio de aprendizaje. (Ver Figura 47 en el Apéndice). Para la validación se han introducido en la base de datos firmas con ruido de fondo, con rotación y en los casos que se han tenido que repetir autores, se han utilizado muestras distintas a las del aprendizaje, por lo que los dos conjuntos de firmas son disjuntos.
Firmas a comparar
Patrones
Figura 47. Tabla de validación
Obteniendo una tabla de resultados correcta, de las 400 comparaciones realizadas ha obtenido un 100% de fiabilidad en el reconocimiento, es decir con índices de similitud más altos en las diagonales que en el resto.
Además las clases siguen siendo linealmente separables, es decir que las firmas más diferentes del mismo autor 4-1 y la 4-2 con un 52% (de verde en la Figura 47) son más parecidas, que las firmas más iguales de distintos autores 6-1 y la 3-2 con un 44% (de azul en la Figura 47).
Por lo tanto, si se mantiene el límite inferior de verificación UV=51% obtenido en el aprendizaje a partir del cual el sistema puede decidir si dos firmas son iguales se obtiene también, un índice de fiabilidad del 100% en la verificación.
7. Discusión y conclusión
Con los resultados anteriores, la funcionalidad de reconocimiento, es decir, buscar en una base de datos de firmas aquella que más se parezca a una dada, el sistema ha obtenido unos resultados muy buenos diferenciando siempre entre las firmas del mismo autor y el resto.
Sin embargo, para el problema de la verificación, en la que se debe de dar un criterio de confianza al decir que dos firmas son iguales, hay que determinar un umbral de similitud (UV) a partir del cual el sistema dirá que son iguales. En este caso, es fácil intuir que a pesar de los buenos resultados obtenidos en la validación, cuanto mayor sea la base de datos de firmas, las clases no van a ser linealmente separables por lo que se comenzará a cometer errores si no se utiliza algún nuevo método para clasificar clases linealmente no separables, como un clasificador estadístico [34], o una red de neuronas. Para estos casos, se podría, por ejemplo, ampliar la etapa de clasificación (distance matching) con una combinación de clasificadores consiguiendo hacer más robusta la verificación.
Dependiendo de la utilidad que se le quiera dar al sistema se podrá modificar el valor a partir del cual se darán por buenas dos firmas (UV) ya que, si se elige un valor muy grande (por ejemplo UV=80%) se forzará a que las firmas sean muy parecidas, pudiéndose dar por falsas dos firmas que realmente son del mismo autor, estos casos se denominan falsos negativos, y si por el contrario, se elige un umbral muy pequeño (por ejemplo UV=40%) se darán por buenas firmas que son de distintas personas, estos casos se conocen por falsos positivos.
Otra posible mejora para hacer el sistema más robusto frente a rotaciones, sería añadir una nueva etapa de preproceso que realizara el cálculo del eje de inercia de la firma y de esta forma rotarla para hacer que este eje formase un ángulo de 0º con la horizontal.
En este proyecto las operaciones sobre la imagen se realizan con una profundidad de color de 24 bits para ayudarnos del color y hacer más sencillo la explicación de los proceso, pero una implementación del esqueletizado, el etiquetado de píxeles, el seguimiento y extracción de trazos sobre la imagen con una profundidad de color de 8bits, mejoraría el rendimiento en tiempo en un 50% al reducirse los tiempos de carga y descarga de las imágenes de disco a memoria y hacer innecesario el trabajo sobre las tres componentes del color (rojo, verde y azul) y la complejidad en memoria en un 66%.
Actualmente la base de datos de firmas sobre la que se realiza el reconocimiento consta simplemente de un directorio (llamado BD) donde se almacena una imagen de cada patrón de cada clase en formato .bmp, este modelo es apropiado para los casos en los que el número de firmas sea pequeño, ya que se compara la firma que se quiere reconocer, con todas las firmas que forman parte de la base de datos. Sin embargo, el sistema podría ser escalable si organizamos las firmas por el número total de trazos, o jerárquicamente por la cantidad de trazos horizontales, verticales, etc. De esta manera, cada firma se compararía con las firmas similares, mejorando los tiempos de respuesta del sistema, si ha esto se le añade que en lugar de almacenar directamente los bitmaps o mapas de bits se almacenaran en la base de datos las listas de los trazos que la componen, además de reducir significativamente las necesidades de espacio en disco, supondría una importante mejora en tiempo pues no sería necesario extraer los trazos de la firma patrón, que es el proceso más costoso (esqueletizado, cuatro filtros de matrices de convolución y cuatro seguimiento y extracción de los trazos, cálculo de la caja de Feret y normalización).
7.1.1. Complejidad en tiempo
La complejidad del sistema como se ha ido viendo a lo largo de la memoria, depende linealmente del número de píxeles de la imagen, ya que es una cota superior respecto al número de trazos de la firma.
Se han realizado cálculos de rendimiento sobre un AMD XP 2.1 Ghz, utilizándose imágenes digitalizadas a una resolución de 200ppp y aproximadamente unas dimensiones de 400x400 píxeles, obteniéndose unos tiempos medios por comparación de 205ms. Aunque no hay que olvidar que es un parámetro que está fuertemente ligado a la muestra utilizada.
También se ha utilizado un ordenador portátil, con un microprocesador Mobile AMD AthlonTM 4 a 1.2 Ghz, con las mismas imágenes y se ha obtenido un tiempo medio de comparación de 319ms.
7.1.2. Complejidad en memoria
Cada firma digitalizada a 200ppp, en blanco y negro ocupa en disco menos de 30Kb. Permitiendo crear bases de datos de miles de firmas de forma sencilla, incluso si se quisiera mejorar este parámetro se podría almacenar únicamente la información de los trazos reduciéndose el tamaño necesitado por firma a apenas 1Kb. mejorándose también y de forma significativa, el rendimiento en tiempo, al ser innecesario la ejecución de los algoritmos necesarios para etiquetar y extraer los trazos de la firma patrón, que son los procesos más costosos, como se ha visto anteriormente.
Durante cada fase del proceso y en el peor de los casos se mantienen en memoria dos copias de la firma, la original y la copia sobre la que se realizan las modificaciones, como todas las operaciones se realizan con una profundidad de color de 24bits, cada firma ocupa en memoria menos de 900Kb. Por lo tanto la aplicación, que en estado de reposo necesita 3.240Kb. de memoria en pleno trabajo de reconocimiento no necesita más de 4.200Kb.
7.1.3. Otra métrica de interés
La aplicación de pruebas e investigación esta formada por 4.491 líneas de código, el tamaño del código compilado es de 568.484 bytes y el de datos de 8.741 bytes, con un tamaño inicial de la pila de 16.384 bytes y un tamaño total en disco del ejecutable de 859.136 byes.
La aplicación definitiva de reconocimiento y verificación consta de 2.543 líneas de código, con un tamaño compilado para el código de 571.000 bytes, 8.573 bytes para datos, con un tamaño inicial de pila de 16.384 bytes y el ejecutable ocupa 842.752 bytes en disco.
A. Base de datos de firmas
Firmas utilizadas en el proceso de aprendizaje
Firma 1-1
Firma1-2
Firma 2-1
Firma 2-2
Firma 3-1
Firma 3-2
Firma 4-1
Firma 4-2
Firma 5-1
Firma 5-2
Firma 6-1
Firma 6-2
Firma 7-1
Firma 7-2
Firma 8-1
Firma 8-2
Firma 9-1
Firma 9-2
Firma 10-1
Firma 10-2
Figura 48. Base de datos de aprendizaje
Firmas utilizadas en el proceso de Validación
Firma 1-1
Firma1-2
Firma 2-1
Firma 2-2
Firma 3-1
Firma 3-2
Firma 4-1
Firma 4-2
Firma 5-1
Firma 5-2
Firma 6-1
Firma 6-2
Firma 7-1
Firma 7-2
Firma 8-1
Firma 8-2
Firma 9-1
Firma 9-2
Firma 10-1
Firma 10-2
Figura 49. Base de datos validación
B. Implementación
El proyecto se ha realizado en Borland Delphi 6 profesional cuyo lenguaje de programación es Object Pascal por sus facilidades gráficas, el conocimiento previo y por el buen rendimiento del código producido. Los ejecutables son aplicaciones para los sistemas operativos de Microsoft, aunque recompilándolos con el compilador de Borland Kylix, funcionarían en Linux sin apenas modificación.
Como se ha dicho ya, uno de los requisitos no funcionales que se ha impuesto al proyecto, es el diseño modular, tanto de las funciones y procedimientos gráficos respecto a la interfaz gráfica para facilitar su reutilización como que dentro de ellas, en todo momento este clara la separación de los datos con la funcionalidad, es decir, en cualquier fase de la ejecución se pueden extraer los resultados y visualizarlos o bien mandarlos a otra máquina o procesador para la ejecución de la siguiente fase, facilitando con ello la ejecución en paralelo.
Estos son los procedimientos y funciones gráficas implementados en la unidad uproyecto.pas, no todas son necesarias para el reconocimiento y verificación de firmas pero si que han sido de ayuda en los pasos previos del estudio.
- function PalabraNo(cont: integer; s: string): string;
--POST: Devuelve la palabra que ocupa la posición cont en la cadena s
- function Ajustar255(valor: integer): integer;
--POST: Ajusta valor al intervalo 0-255. Necesario al modificar el brillo y contraste en imágenes de 24bits de color.
- function Mediana(valores: array of integer): integer;
--POST: Devuelve la mediana de los valores del array de enteros.
- function ValorPixel(valor: TRGBTriple): integer;
--POST: función que Devuelve 0 si valor representa un píxel de color blanco y 1 en otro caso.
- function EsqueletizadoTest1(var origenBmp: TBitmap): boolean;
--POST: función que marca para borrar los píxeles de origenBmp si cumplen con las condiciones del Test1 del algoritmo de esqueletizado de Zhang y Suen. Devuelve true si se ha modificado algún píxel, false en caso contrario.
- function EsqueletizadoTest2(var origenBmp: TBitmap): boolean;
--POST: función que marca para borrar los píxeles de origenBmp si cumplen con las condiciones del Test2 del algoritmo de esqueletizado de Zhang y Suen. Devuelve true si se ha modificado algún píxel, false en caso contrario.
- procedure BorrarPixelsMarcados(var origenBmp: TBitmap; r,g,b: integer);
--POST: Borra los píxeles marcados del color (r,g,b) en el test1 y test2 para ser borrados.
- procedure Esqueletizar(var origenBmp, destinoBmp: TBitmap);
--POST: Devuelve en destinoBmp la imagen esqueletizada de origenBmp.
- procedure Convolucion(var origenBmp, destinoBmp: TBitmap; matriz: TipoMatrizConvolucion; divisor: integer);
--POST: Aplica sobre origenBmp la matriz de convolución matriz con el factor de división divisor y el resultado lo Devuelve en destinoBmp.
- procedure SacarTrazos(var origenBmp: TBitmap; var trazos: TStringList; micolor: TColor);
--POST: Extrae de origenBmp, los trazos del color micolor y los almacena en trazos que es una lista de strings de la forma color x_inicio y_inicio x_fin y_fin.
- procedure LimitesFirma(var origenBmp: TBitmap; var minX, maxX, minY, maxY: TPoint);
--POST: Devuelve en minX, maxX, minY, maxY, las coordenadas extremas de la firma (caja de Feret de la firma completa) contenida en origenBmp.
- procedure LimitesTrazos(var trazos: TstringList; var minX, maxX, minY, maxY: TPoint);
--POST: Devuelve en minX, maxX, minY, maxY, las coordenadas extremas de la firma (caja de Feret de los trazos) contenida en trazos.
- procedure NormalizarPunto(var punto, minX, maxX, minY, maxY: TPoint);
--POST: Normaliza las coordenadas de punto respecto a los límites minx, maxX, minY, maxY.
- procedure Normalizar(var trazos: TStringList; var minX, maxX, minY, maxY: TPoint);
--POST: Normaliza todos los trazos contenidos en trazos respecto a los límites minX, maxX, minY, maxY.
- function CompararFirmas(trazos1, trazos2: TStringList): double;
--POST: Función que Devuelve el porcentaje de similitud entre las listas de trazos trazos1 y trazos2.
- procedure PuntosExtremos(var origenBmp: TBitmap);
--POST: Procedimiento que dibuja en origenBmp, todos los puntos extremos que encuentra. Punto extremo es aquel que sólo tiene un 8-vecino.
- procedure Rotar(var origenBmp, destinoBmp: TBitmap; ejex, ejey: integer; angulo: double);
--POST: Rota origenBmp un ángulo angulo tomando como ejes de giro ejex, ejey y el resultado lo Devuelve en destinoBmp.
- procedure Brillo(var origenBmp, destinoBmp: TBitmap; valor: integer);
--POST: Aplica sobre origenBmp un incremento/decremento del brillo determinado por valor. Devuelve la imagen modificada en destinoBmp.
- procedure Contraste(var origenBmp, destinoBmp: TBitmap; valor: integer);
--POST: Aplica sobre origenBmp un incremento/decremento del contraste determinado por valor. Devuelve la imagen modificada en destinoBmp.
- procedure Filtro_Mediana(var origenBmp, destinoBmp: TBitmap);
--POST: Devuelve en destinoBmp, el resultado de aplicar el filtro mediana en la imagen origenBmp;
- procedure BichoRaro(var origenBmp, destinoBmp: TBitmap; valor: integer);
--POST: Devuelve en destinoBmp, el resultado de aplicar el filtro bicho raro en la imagen origenBmp, con el valor de discordancia determinado por valor;
C. Breve manual de usuario
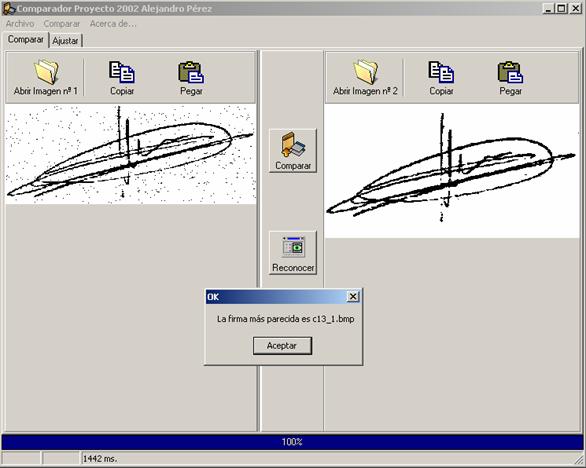
El programa de reconocimiento y verificación de firmas tiene esta interfaz (Figura 50). Para reconocer una firma, basta con en el botón Abrir Imagen nº1 y seleccionar el archivo que contiene la firma y se abrirá en la zona izquierda de la ventana. Posteriormente, hacer clic en el botón Reconocer y se buscará en la base de datos (directorio BD desde la ruta de instalación del programa) la firma que más se parezca a la abierta. Abriendo el resultado en la ventana de la derecha y mostrará un mensaje con el nombre de la firma encontrada. En la barra de estado queda reflejado el tiempo empleado en el proceso.
Figura 50. Reconocimiento de firmas
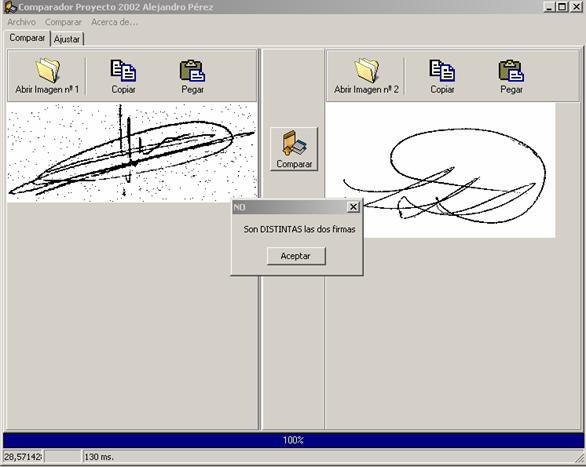
Para comparar dos firmas, hay que hacer clic en el botón Abrir Imagen nº1 y seleccionar el archivo que contiene la firma y se abrirá en la zona izquierda de la ventana. Hacer lo mismo con el botón Abrir Imagen nº2, una vez se vean las dos firmas, hacer clic en el botón Comparar y se mostrará un mensaje con el resultado de la verificación. En la barra de estado queda reflejado el tiempo empleado en el proceso, y en el transcurso de la comparación la barra de progreso indicará el porcentaje del trabajo realizado. En la barra de estado también queda reflejado el índice de similitud calculado.
Figura 51. Verificación de firmas
Interacción con el exterior (Copiar, Pegar, Drag & Drop, Abrir y Guardar)
Para abrir una imagen en el comparador se puede hacer como se ha visto anteriormente por medio de los respectivos botones de Abrir Imagen, también se puede hacer a través del portapapeles, pinchando en el botón Pegar, e incluso utilizando el ratón arrastrando y soltando en la zona de la ventana que queramos, el archivo .bmp que contiene la firma. Por último, se puede Copiar en el portapapeles cualquiera de las imágenes abiertas en la aplicación.
D. Grafología
La palabra grafología proviene del griego grafo, que significa trazo y logos, que significa ciencia.
Para realizar una correcta evaluación de la persona analizada, ésta debe escribir una carta manuscrita personal que lleve su firma, en letra cursiva minúscula y preferentemente en lápiz o con bolígrafo en su defecto. Se debe realizar en una hoja de papel blanco, tamaño carta y sin renglones. El texto debe ser espontáneo [38].
Para la Ciencia Grafológica, el grafo-análisis es una disciplina basada en la interpretación de factores escriturales, tales como inclinación, dirección, forma, dimensión, velocidad, presión, continuidad y orden; dentro de este último se hallan la disposición, la distribución y la proporción. En grafología cualquier tipo de accidente gráfico como: invasión de zonas (márgenes), temblores, borrones, tachaduras o enmiendas, fracturas de letras, puntos fuera de lugar, retoques de letras, mayúsculas sobrealzadas, achiques o agrandamientos de letras, palabras o letras inconclusas, etc., son elementos que revelan la clave para definir el conflicto íntimo de ese acto fallido en la escritura.
Tuvo su origen en el siglo XVII. Camilo Baldo, profesor de Filosofía de la Universidad de Bolonia, publicó el Tratado sobre cómo a través de una carta manuscrita se conoce la naturaleza y cualidad del que escribe.
Médicos, poetas, filósofos y varios escritores se volvieron aficionados a lo que Juan Hipólito Michón, abate francés, daría por llamar Grafología. El padre de esta ciencia fundó en 1871 la Sociedad Francesa de Grafología y fue él quien organizó un sistema completo titulado Los misterios de la escritura. Estableció en él una clasificación en siete géneros para su análisis, que posteriormente extendió a ocho la investigadora francesa Madamme de Saint Morín.
En 1885, Jules Crepieux-Jamin, discípulo de Michón, coordinó los resultados de éste y fijó otras leyes para la clasificación e interpretación de los géneros. Asimismo relacionó la escritura con la mímica del cuerpo. Sus obras, producto de largas experiencias, son Tratado práctico, La escritura y el carácter, La edad y el sexo en la escritura, Los elementos de la escritura en los canallas y finalmente el ABC de la grafología.
En 1900, Ludwing Klages, caracterólogo y filósofo alemán, recogió lo de sus antecesores e inició así su propia escuela, basada en la esencia de que la escritura es la expresión gráfica del conflicto que yace en el individuo entre lo mental, por un lado, y los impulsos naturales y síntomas que resultan de la actividad humana, por el otro. Klages fundó la Sociedad Alemana de Grafología y de este modo se inicia la era científica de esta disciplina. Sus obras son Problemas de grafología, Fundamentos de la ciencia y el carácter, Expresión del carácter en la escritura.
El otro maestro, considerado uno de los genios de la grafología moderna, es el suizo doctor Max Pulver, quien introdujo la psicología en el análisis de la escritura. En 1931 publicó su famosa obra El simbolismo del espacio. Tomando la teoría psicoanalítica de Freíd. Pulver expresaba: Que el que escribe confecciona su propio retrato, haciendo referencia a que en la escritura se refleja la vida consciente e inconsciente de quien escribe.
Bibliografía
[1] Fuente: Sistemas de Documentación Multimedia, S. L.
[2] Fuente: http://www.a2ia.com
[3] Patrick Henry Winston. Artificial Intelligence. Addisson Wesley, Reading, MA, second edition, 1992.
[4] Especificación del formato de archivos bmp http://atlc.sourceforge.net/bmp.html
[5] Grafología http://www.forgeryfinder.com/Hand.htm
[6] T. Y. Zhang and C. Y. Suen. A fast parallel algorithm for thinning digital patterns. In Communications of the ACM, volume 27, pages 236-239, 1984.
[7] L. da Fontoura Costa y R. Marcondes Cesar Jr., Shape Analisis and Classification. CRC Press, 2001.
[8] Bajcsy R and Kovacic S. Multiresolution elastic matching. Comp. Vision, Graphics and Image Proc. 46:1-21. 1989.
[9] J. R. Parker. Algorithms for image processing and computer vision. Wiley Computer Publishing.
[10] P. Scattolin. Recognition of handwritten numerals using elastic matching. Master's thesis, Concordia University, 1995.
[11] R.K. Powalka. An algorithm toolbox for on-line cursive script recognition. PhD thesis, The Nottingham Trent University, 1995.
[12] E. Vidal UPV: Febrero, 2002 Apuntes Aprendizaje y Percepción. Facultad de Informática Universidad Politécnica de Valencia.
[13] Kenneth R. Castleman. Digital Image Processing. Prentice Hall, Upper Saddle River, NJ, 1996.
[14] Javier González Jiménez. Visión por Computador. Paraninfo.
[15] Rafael C. González. Richard E. Woods. Digital Image Processing. Addison-Wesley publishing company.
[16] D. Rubine. Specifying gestures by example. Technical report, Information Technology Center, Carnegie Mellon University, 1993.
[17] José Francisco Vélez, Ángel Sánchez, José Luis Esteban. Apuntes Visión Computacional. Ingeniería T. Informática de Sistemas Universidad de Rey Juan Carlos de Madrid.
[18] P. Simard. Tangent prop - a formalism for specifying selected invariances in an adaptive network. Advances in Neural Information Processing Systems 4, 4, 1992.
[19] José Manuel Quero Reboul. Apuntes Redes Neuronales. Ingeniería Electrónica Universidad de Sevilla.
[20] LeCun et al. Gradient-based learning applied to document recognition. In Proceedings of the IEEE, november 1998. LeCun et al. Handwritten digit recognition with a back-propagation network. Advances in Neural Information Processing Systems 2, 1990.
[21] S. Haykin. Neural Networks - A Comprehensive Foundation. Prentice-Hall, 1994.
[22] T. Kohonen. Learning vector quantization for pattern recognition. Technical report, Helsinki University of Technology, Finland, 1986.
[23] S. Haykin. Neural Networks - A Comprehensive Foundation. Prentice-Hall, 1994.
[24] Stefan Hellkvist. On-line character recognition on small hand-held terminals using elastic matching. Master´s thesis, Royal Institute of Technology, Stockholm, 1999.
[25] Y. Choe. Lateral interconnected self-organizing maps in hand-written digit recognition. Advances in Neural Information Processing Systems 8, 1996.
[26] Jaime Silvela Maestre. Sistema eficiente de reconocimiento de gestos de la mano. PFC E.T.S.I. Telecomunicación. Universidad Politécnica de Madrid, 2000.
[27] J. R. Parker. Practical Computer Vision using C. John Wiley & Sons, New York, 1993.
[28] F. Alimoglu. Combining multiple classifiers for pen-based handwritten digit recognition. Master's thesis, Bogazici University, 1994.
[29] P. Simard. Efficient pattern recognition using a new transformation distance. Advances in Neural Information Processing Systems, 5, 1993.
[30] R.H. Kassel. A Comparison of Approaches to On-line Handwritten. PhD thesis, Massachusetts Institute of Technology (MIT), 1995.
[31] M.K. Brown and S. Ganapathy. Preprocessing techniques for cursive script word recognition. Pattern Recognition, 16:447,458, 1983.
[32] Kam-Fai Chan and Dit-Yan Yeung. Elastic structural matching for recognizing on-line handwritten alphanumeric characters. Technical report, Department of Computer Science, Hong Kong University, 1998.
[33] Dann R, Hoford J, Kovacic S, Reivich M, and Bajcsy R. 1989. Evaluation of elastic matching systems for anatomic (CT,MRI) and functional (PET) cerebral images. J Comput Assist Tomogr. 13(4):603-611.
[34] Athanasios Papoulis. Probability, Random Variables, and Stochastic Processes. McGraw-Hill, New York, third edition, 1991.
[35] G. Sánchez P., K. Toscano M., Nakano M. y H. Pérez M. Método para el Reconocimiento de Firmas utilizando Envolventes y Parámetros Estadísticos. 1er. Congreso Internacional en Electrónica, Comunicaciones y Computación. CIECC´99, Marzo 1999
[36] K. Toscano M., G. Sánchez P., Nakano M. y H. Pérez M. Reconocimiento de Firmas por Medio de Extracción de Características. Proc. Of 2nd. Internacional Congreso of Research in electrical and Electronics Engineering, CIIIEE´98, Sep. 1998.
[37] K. Toscano M., G. Sánchez P., Nakano M. y H. Pérez M. Reconocimiento de Firmas usando un arreglo de Perceptrones Multicapas. Escuela Superior de Ingeniería Mecánica y Eléctrica Unidad Culhuacan, IPN, Mexico D.F.
[38] http://www.handwriting.org y http://www.forgeryfinder.com/Hand.htm